再次复习下ASCII码,unicode,utf-8是怎么回事:
最初的编码是ASCII码,每个英文占1字节,不能存储中文;为了统一世界各国的编码出现了unicode,但是在unicode中不管中文英文都占2字节,也就是原本1M的文件变成了2M,
造成了空间浪费;于是出现了unicode的扩展版本utf-8,在utf-8中英文仍然按照ASCII码的规则占1字节,汉字占3字节。
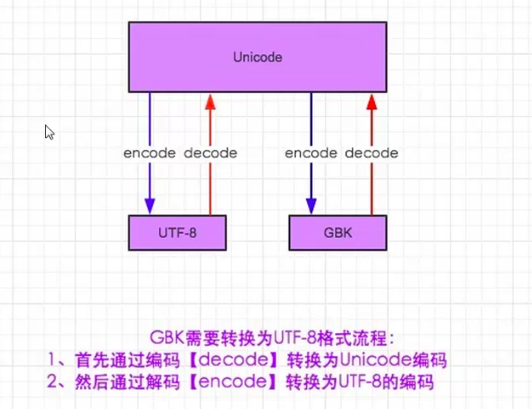
GBK和UTF-8如何转换:(中文windows默认编码集是gbk),utf-8和unicode之间不转换是可以互相打印的,但是gbk和unicode之间必须转换才能打印
#! /usr/bin/env python # -*- coding: utf-8 -*- #特别注意,这个只是声明文件编码,所以见下个# # __author__ = "Deakin" # Email: 469792427@qq.com # Date: 2018/1/8 import sys print(sys.getdefaultencoding()) s="你好" #这里的s的默认编码仍然是unicode,不是utf-8 s_gbk=s.encode("gbk") print(s) print(s_gbk) print(s_gbk.decode('gbk')) 打印结果:
utf-8
你好b'\xc4\xe3\xba\xc3' #encode的时候转换成了bytes你好 #再次decode回unicode又转成了字符串